近日,厦门大学多媒体可信感知与高效计算教育部重点实验室在国际顶级学术会议international conference on computer vision(iccv)上录用13篇论文。实验室接收论文简要介绍如下:
1. category-aware allocation transformer for weakly supervised object localization
弱监督目标定位(wsol)旨在实现,仅给定图像级标签的前提下学习一个目标定位器。最近,基于自注意力机制和多层感知器结构的变换神经网络(transformer)因其可以捕获长距离特征依赖而在wsol中崭露头角。美中不足的是,基于transformer的方法使用类别不可知的注意力图来预测边界框,从而容易导致混乱和嘈杂的目标定位。本文提出了一个基于transformer的新颖框架——catr(类别感知transformer),该框架在transformer中学习特定目标的类别感知表示,并为目标定位生成相应的类别感知注意力映射。具体来说,本文提出了一个类别感知模块来引导自注意力特征图学习类别偏差,并且提供类别监督信息来指导其学习更有效的特征表示。此外,本文还设计了一个目标约束模块,以自我监督的方式细化类别感知注意力图的目标区域。最后,在两大公开数据集cub-200-2011和ilsvrc上进行了充分的实验,验证了本文方法的有效性。
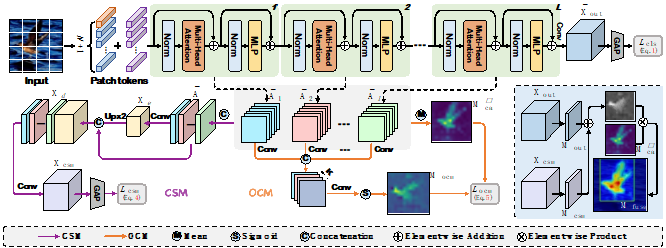
该论文第一作者是厦门大学信息学院人工智能系2020级博士生陈志威,通讯作者是曹刘娟教授,由沈云航(优图实验室)、张声传助理教授、纪荣嵘教授等合作完成。
2. pseudo-label alignment for semi-supervised instance segmentation
该论文面向半监督实例分割任务,针对现有方法的一个局限性,即伪标签的类别和掩模质量的不匹配问题,提出了一种新颖的框架,称为pais。论文在pais中设计了一种动态对齐损失函数(daloss),它可以调整具有不同类别和掩模分数对的半监督损失函数项的权重,以此来缓解不匹配的问题。论文通过在coco 和 cityscapes 数据集上进行的广泛实验,证明 pais 是半监督实例分割的一个有效框架,特别是在有标签数据严重有限的情况下。
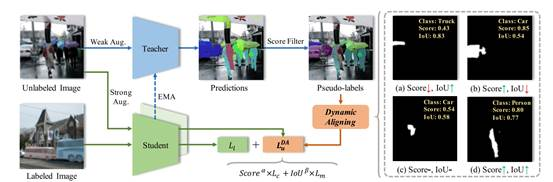
该论文共同第一作者是厦门大学信息学院2019级博士生胡杰和2021级硕士生陈晨,通讯作者是曹刘娟教授,由张声传助理教授、束岸楠(宁德时代)、江冠南(宁德时代)、纪荣嵘教授合作完成。
3.interformer: real-time interactive image segmentation
该论文提出了一种高效的图像交互分割方法,称为interformer,用于解决现行交互分割流程中存在的模型低并行处理以及计算冗余问题。interformer先利用vision transformer在高性能设备上并行预处理图像,后基于预处理后的图像特征以及所提出的交互多头自注意力模块(i-msa)可在低性能的端设备上进行实时的交互分割。经过多个数据集上的实验验证,interformer在计算效率和分割质量上均表现卓越,甚至在只使用cpu的设备上,也能实现实时的高质量交互分割。
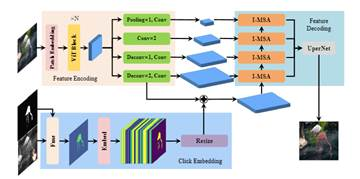
该论文第一作者是厦门大学信息学院人工智能系2022级博士生黄有,通讯作者是张声传助理教授,由曹刘娟教授,江冠南博士(宁德时代),纪荣嵘教授等共同合作完成。
4.x-mesh: towards fast and accurate text-driven 3d stylization via dynamic textual guidance
本文提出了一个用于文本驱动 3d 风格化任务的新框架,称为 x-mesh,它采用了动态文本指导机制。在预测 mesh 属性过程中,x-mesh 引入早期的动态文本指导,从而实现更快的收敛速度和更精准的编辑效果。同时,在以往的文本驱动 3d 风格化任务中,往往需要人工进行效果评估,且缺乏标准的测试数据集,因此难以进行公平的比较。为此,本文提出了一个专门用于文本驱动 3d 风格化任务的测试集,并基于 clip 模型提出了两个定量指标,以便更好地促进该领域的研究。
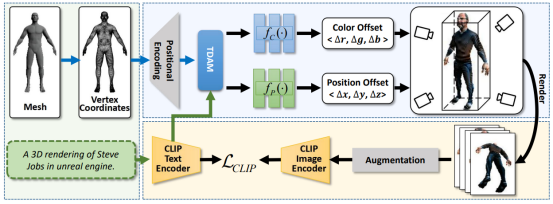
该论文共同第一作者是厦门大学信息学院人工智能系2020级研究生马祎炜和人工智能研究院2022级研究生张晓庆,通讯作者是孙晓帅副教授,由江冠南博士(宁德时代)、纪荣嵘教授等合作完成。
5.automatic network pruning via hilbert-schmidt independence criterion lasso under information bottleneck principle
大多数现有的神经网络剪枝方法都是手工设计其重要性标准和结构以进行剪枝。这对于专家经验有着严重的依赖。本文通过引入基于信息瓶颈理论的一个原则性和统一性框架来解决这个问题,从而指导提供了一个能够实现自动剪枝的方案。具体而言,本文首先从信息瓶颈的角度对通道剪枝问题进行了建模,然后在一定条件下通过解决希尔伯特-施密特独立准则(hsic)lasso问题来实现信息瓶颈原则。基于理论指导,本文提供了一个通过搜索全局惩罚系数来实现自动剪枝的方案。通过广泛的实验证明,本文提出的方法在各种基准网络和数据集上取得了最先进的性能。例如,使用resnet-50,在去除50%的参数的同时,减少了56%的计算量,并且剪枝后的模型在imagenet上的准确率仅仅损失了0.08%。
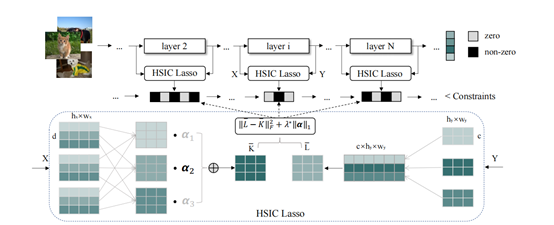
该论文共同第一作者是厦门大学信息学院人工智能系2021级研究生硕士生郭颂、2021级硕士生张雷和郑侠武博士(鹏城实验室),通讯作者是纪荣嵘教授,由王言博士(samsara inc.)、李与超(阿里巴巴)、晁飞副教授、张声传助理教授等共同合作完成。
6.smmix: self-motivated image mixing for vision transformers
cutmix是一种重要的数据增强策略,对于视觉变换器(vits)的性能和泛化能力至关重要。然而,混合图像与相应标签之间的不一致性会损害其有效性。现有的cutmix变体通过生成更一致的混合图像或更精确的混合标签来解决这个问题,但不可避免地引入了沉重的训练开销或需要额外的信息,从而削弱了使用的便利性。为此,该论文提出了一种新颖而有效的自我激励图像混合方法(smmix),该方法通过训练模型本身来激励图像和标签的增强。具体而言,论文提出了一种最大-最小注意力区域混合方法,丰富了混合图像中的注意力聚焦对象;接着引入了一种细粒度标签分配技术,通过细粒度监督来共同训练混合图像的输出标记。此外,该论文设计了一种新颖的特征一致性约束,以使混合图像和未混合图像的特征对齐。由于自我激励方式的微妙设计,smmix在降低训练开销和性能方面具有显著优势,特别是在imagenet-1k数据集上,smmix将deit-t/s/b,cait-xxs-24/36和pvt-t/s/m/l的准确性提高了超过 1%。该论文提出的方法的泛化能力还在下游任务和分布外数据集上得到了证明。
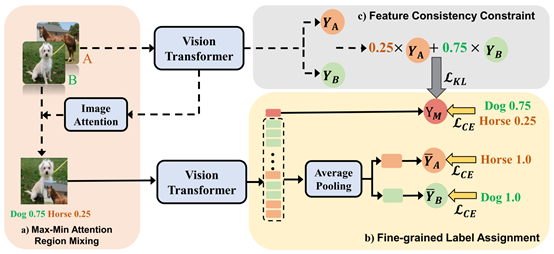
该论文第一作者是厦门大学信息学院人工智能系2021级硕士生陈锰钊,通讯作者是纪荣嵘教授,由林明宝(腾讯优图)、2022级硕士生林志航、2022级博士生张玉鑫和晁飞副教授等共同合作完成。
7. diffrate: differentiable compression rate for efficient vision transformers
令牌压缩旨在通过修剪(丢弃)或合并令牌来加速大规模视觉变换器(例如vits),这是一项重要而具有挑战性的任务。虽然最新的一些方法取得了巨大的成功,但它们需要精心制定压缩率(即要删除的令牌数量),这是一项繁琐的工作,且会降低性能。为了解决这个问题,该论文提出了可微分压缩率(diffrate),其具有以下特性:首先,diffrate能够将损失函数的梯度传播到压缩率上,不同的层可以自动学习不同的压缩率,无需额外的开销,而在以前的工作中,压缩率被视为不可微分的超参数;其次,在diffrate中,令牌修剪和合并可以自然地同时进行,而在以前的工作中它们是独立的;第三,广泛的实验证明diffrate实现了最先进的性能。例如,将学习到的逐层压缩率应用于现成的vit-h(mae)模型,该论文的方法在imagenet上实现了40%的flops减少和1.5倍的吞吐量提高,而准确率仅下降了0.16%,甚至优于以前经过微调的方法。
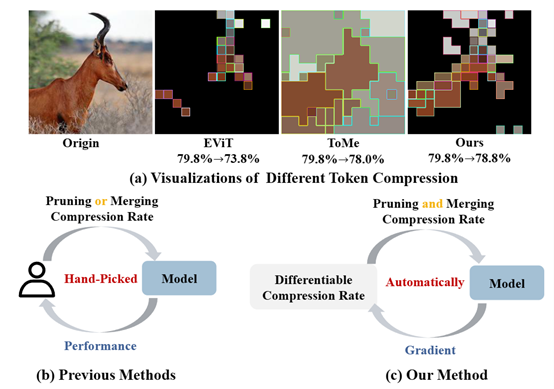
该论文共同第一作者是厦门大学信息学院人工智能系2021级硕士生陈锰钊,和上海人工智能实验室邵文琪,通讯作者是纪荣嵘教授,由晁飞副教授、上海人工智能实验室乔宇教授和罗平教授等共同合作完成。
8.autodiffusion:training-free optimization of time steps and architectures for automated diffusion model acceleration
扩散模型在图像⽣成、图像超分辨率重建等多个领域都获得了令⼈印象深刻的效果,但是这类模型的⽣成过程包含多个时间步,每个时间步需要进⾏⼀次模型前向传播,这导致扩散模型⽣成速度远慢于其它⽣成模型。现有的扩散模型加速⽅法往往通过减少时间步数量以实现加速扩散模型,这些⽅法均使⽤均匀时间步。本⽂认为,均匀时间步不是最优的时间步序列,并且对于每个扩散模型都存在对应的最优时间步序列。因此,本⽂提出在⼀个统⼀的框架内为扩散模型搜索最优的时间步序列以及对应的模型结构,并将这套框架称为autodiffusion。autodiffusion的搜索空间同时包括扩散模型的时间步和模型结构,因此可以从两个正交的⻆度加速扩散模型。同时,autodiffusion使⽤进化算法作为搜索策略,并使⽤fid指标作为性能评估策略,以实现准确快速的搜索。实验结果表⽰,autodiffusion可以显著提⾼扩散模型的⽣成速度与⽣成质量。在imagenet64x64上,autodiffusion在时间步数量为4的条件下搜索得到的最优序列的fid为17.86,相对于均匀时间序列(fid=138.66)极⼤提⾼了扩散模型在极少时间步情况下的⽣成质量。
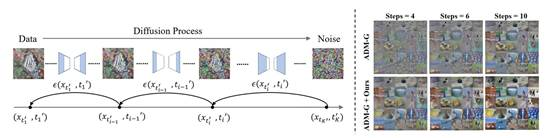
该论⽂第一作者是厦⻔⼤学信息学院⼈⼯智能系2022级研究⽣李漓江,通讯作者是晁⻜副教授,由李慧霞(字节跳动)、郑侠武博士(鹏城实验室)、纪荣嵘教授等共同合作完成。
9.coin:contrastive instance feature mining for 3d object detection with very limited annotations
针对目前三维目标检测器性能依赖于准确三维包围框标注的问题,本论文提出了一个基于稀疏标注的端到端三维目标检测方法,称为coin。该方法设计了多类别对比学习模块(mccont)以增强前景特征之间的特征鉴别力,设计了伪标签挖掘模块(inf-mining)以从未知特征中挖掘潜在伪前景特征,还设计了真伪对比学习模块(lpcont)以保证伪前景特征的正确性。多个数据集上的实验结果验证了coin的有效性,在三维目标检测常用的kitti数据集上,只使用2%的标注量就能达到接近全监督检测器的水平;在waymo和nuscenes大型户外无人驾驶数据集上也大大提升了基线方法的精度。
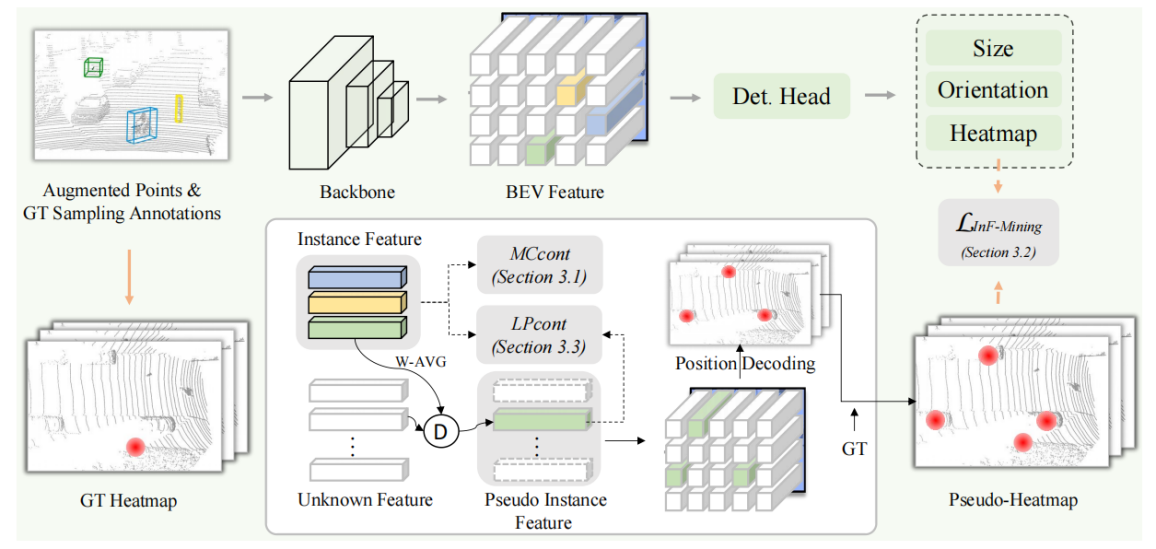
该论文第一作者是厦门大学信息学院人工智能系2022级博士夏启明,通讯作者是温程璐教授,由2021级硕士邓锦豪、2021级博士吴海、shaoshuai shi(max planck institute for informatics)、 xin li(texas a & m university)、王程教授共同合作完成。
10. label-noise learning with intrinsically long-tailed data
该论文探索了一个更加一般化的标签噪声学习场景,即真实长尾分布下的标签噪声学习问题。这个问题的主要挑战在于训练数据标签的观测分布与其真实分布的不一致性,以及在尾部类别中噪声样本和干净样本的难以分离。为了解决上述问题,本文提出了一种名为tabasco的两阶段样本选择方法。第一个阶段,根据模型的输出和特征信息,采用加权js散度和自适应质心距离来逐类分离干净样本和噪声样本;第二阶段,为每个类别确定最优的样本分离维度,并选择相应的干净样本簇;最后,采用半监督学习范式,将选定的干净簇视为标记数据来更新模型。为了公平有效地验证不同方法在该问题下的表现,本文基于red mini-imagenet和cifar-10n/100n构建了两个具有真实世界噪声和真实长尾分布的测试基准。相较于现有方法,tabasco提升了2%至8%的准确率。
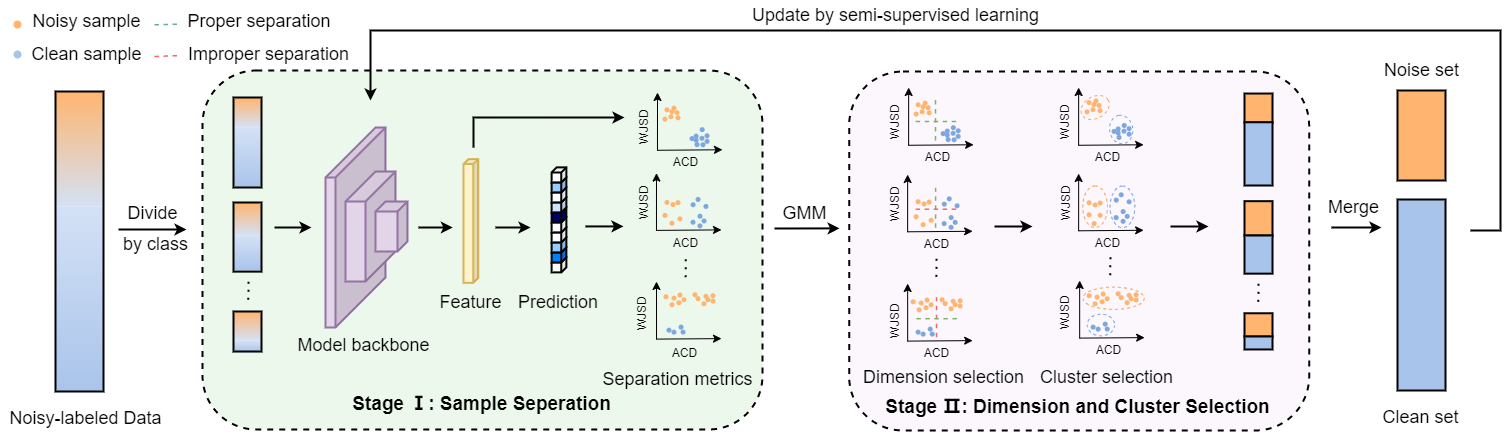
该论文第一作者是卢杨助理教授,通讯作者是王菡子教授,由厦门大学信息学院计算机科学与技术系2021级硕士生张易亮、香港浸会大学韩波助理教授、张晓明教授等共同合作完成。
11.dual pseudo-labels interactive self-training for semi-supervised visible-infrared person re-identification
针对传统的跨模态行人重识别因采用全监督导致标注成本高的问题,该论文探索两种实用的半监督设置:单一半监督(仅标注可见光模态)和双重半监督(部分标注两种模态),并提出适用于这两种半监督跨模态行人重识别的双伪标签交互自训练(dpis)方法。dpis将两个不同模型生成的伪标签融合成一个混合伪标签。然而,混合伪标签中仍然不可避免地包含噪声伪标签。为了消除噪声伪标签的负面影响,论文设计了三种策略:噪声标签惩罚(nlp)、噪声关联校准(ncc)和不可靠锚的对比学习(ual)。nlp对噪声标签进行惩罚,ncc校准噪声关联,ual挖掘难以区分的特征。通过在sysu-mm01和regdb数据集上进行大量实验证明,dpis在这两种半监督设置下取得了非常有效的性能。
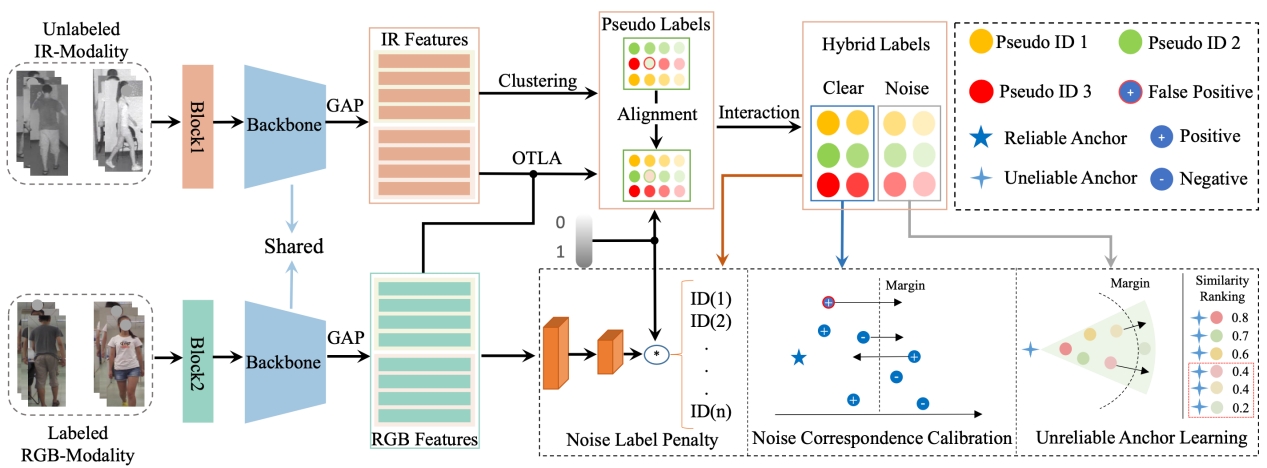
该论文共同第一作者是厦门大学人工智能研究院2022级博士生施江鸣和张亚超博士(清华大学),通讯作者是谢源教授(华东师范大学)和曲延云教授,合作者还有联想公司师忠超研究员和范建平教授等。
12.efficient converted spiking neural network for 3d and 2d classification
脉冲神经网络(snn)因其低功耗和符合生物学规律的特性引起了广泛的关注。现有的人工神经网络(ann)到snn的转换方法可以通过将训练好的ann转换为snn来实现无损转换。然而,转换后的snn需要大量的时间步长才能达到与训练好的ann相媲美的性能,这意味着较高的延迟性。本论文提出了一种高效通用的ann-snn转换方法,用于点云分类和图像分类,以显著减少转换所需的时间步长,实现快速且无损的ann-snn转换。该方法首先根据脉冲神经元的激活状态自适应地调整阈值,确保每个时间步激活一定比例的脉冲神经元,以减少膜电位的累积时间。接着,采用自适应的放电机制来扩大脉冲的输出范围,在短时间步长内获得更具判别性的特征。在具有挑战性的点云和图像数据集上进行了大量实验,实验结果表明该方法显著优于最先进的ann-snn转换方法。
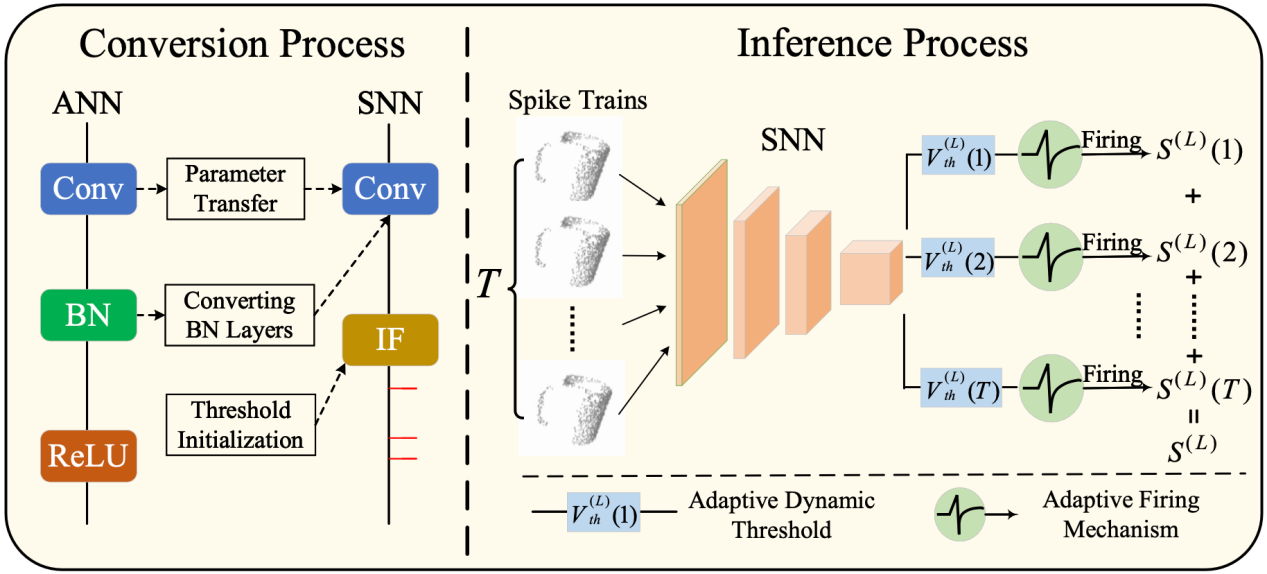
该论文第一作者是厦门大学信息学院计算机科学与技术系2020级硕士生蓝宇翔,通讯作者是张亚超博士(清华大学)和曲延云教授,合作者还有东北大学马旭博士和付云教授等。
13.bev-dg: cross-modal learning under bird’s-eye view for domain generalization of 3d semantic segmentation
该论文提出了鸟瞰视角下的跨模态学习方法(bev-dg),利用多模态数据的互补性解决3d语义分割的领域泛化问题。现有的跨模态学习方法都基于点和像素的映射关系进行。由于激光雷达和相机的外在校准不准确,点级别的映射误差限制了跨模态学习的效果。bev-dg旨在利用鸟瞰视角下的跨模态学习来优化与领域无关的表征建模。首先,提出了基于鸟瞰视角的区域对区域融合(baf),用于在鸟瞰视角下进行跨模态学习,对于点级别的映射误差具有更高的容错性。其次,提出了鸟瞰视角驱动的领域对比学习(bdcl),推动网络学习领域无关的特征。bev-dg在三种领域泛化设定中显著优于现有的竞争对手,取得了最高32%的效果领先。
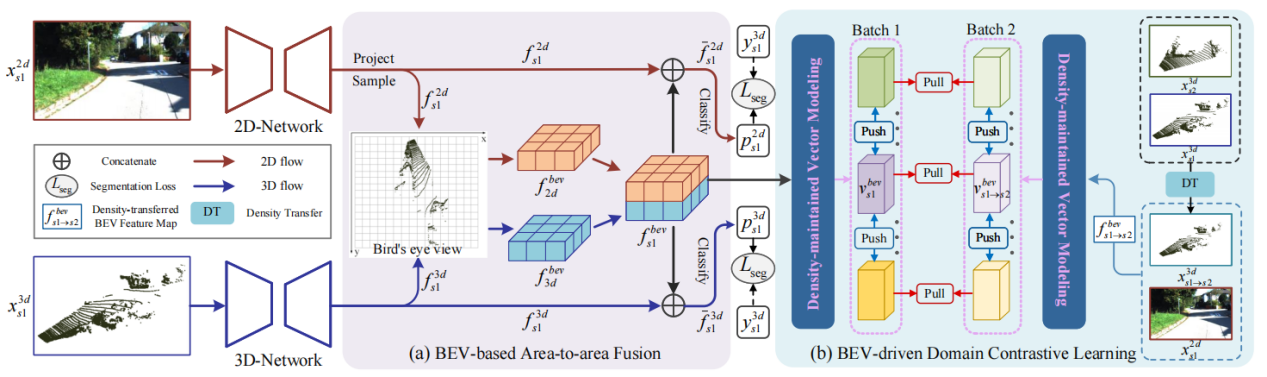
该论文第一作者是厦门大学信息学院计算机科学与技术系2020级硕士生李杪宇,通讯作者是曲延云教授和张亚超博士(清华大学)、合作者还有东北大学马旭博士和付云教授等。
投稿:林颖
